Replicating Deep Research in Jan
What exactly is deep research and how does it work? OpenAI's Deep Research, released in February 2025, generates comprehensive research reports by combining systematic searching with automated synthesis. The process breaks down into two core components:
There are two core features of Deep Research:
- Exhaustive search: All major model providers that offer deep research as a service search from a variety of sources. This can be broken down (largely) into two forms of search: breadth-first search and depth-first search. There will be more of this later.
- Report generation: Most major model providers generate comprehensive reports at the end of the research process. For instance, OpenAI gives users the ability to export its research output as a PDF, while Kimi provides an interactive HTML webpage in their UI for easier visualization.
Unpacking Deep Research
While the outputs of deep research might be mind-blowing at first glance, the underlying process is surprisingly systematic. The crux of Deep Research lies in the base model and its capabilities to use tools that are provided to it.
OpenAI’s Deep Research API cookbook (opens in a new tab) reveals the step-by-step flow they use:
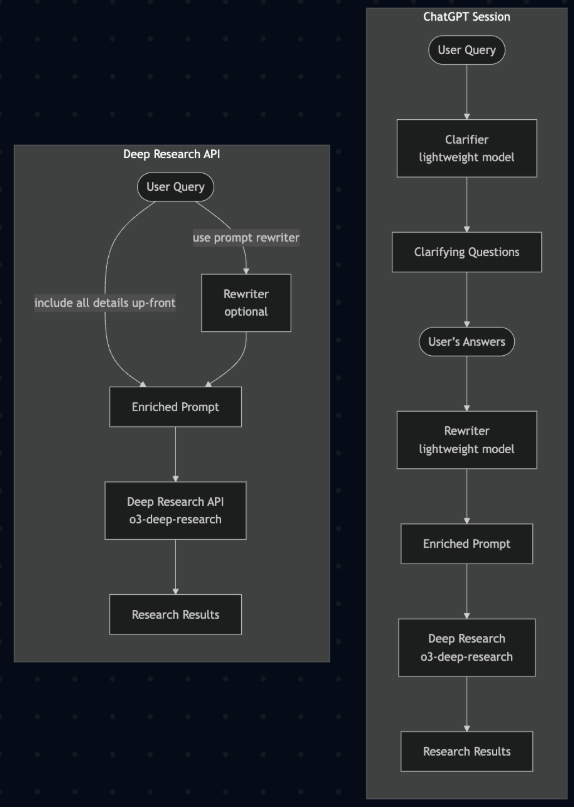
Deep Research operates as a structured pipeline with distinct phases: planning, searching, analysis, and synthesis. While the specific implementation varies between providers, the core workflow remains consistent. For example, a straightforward pipeline might look like this:
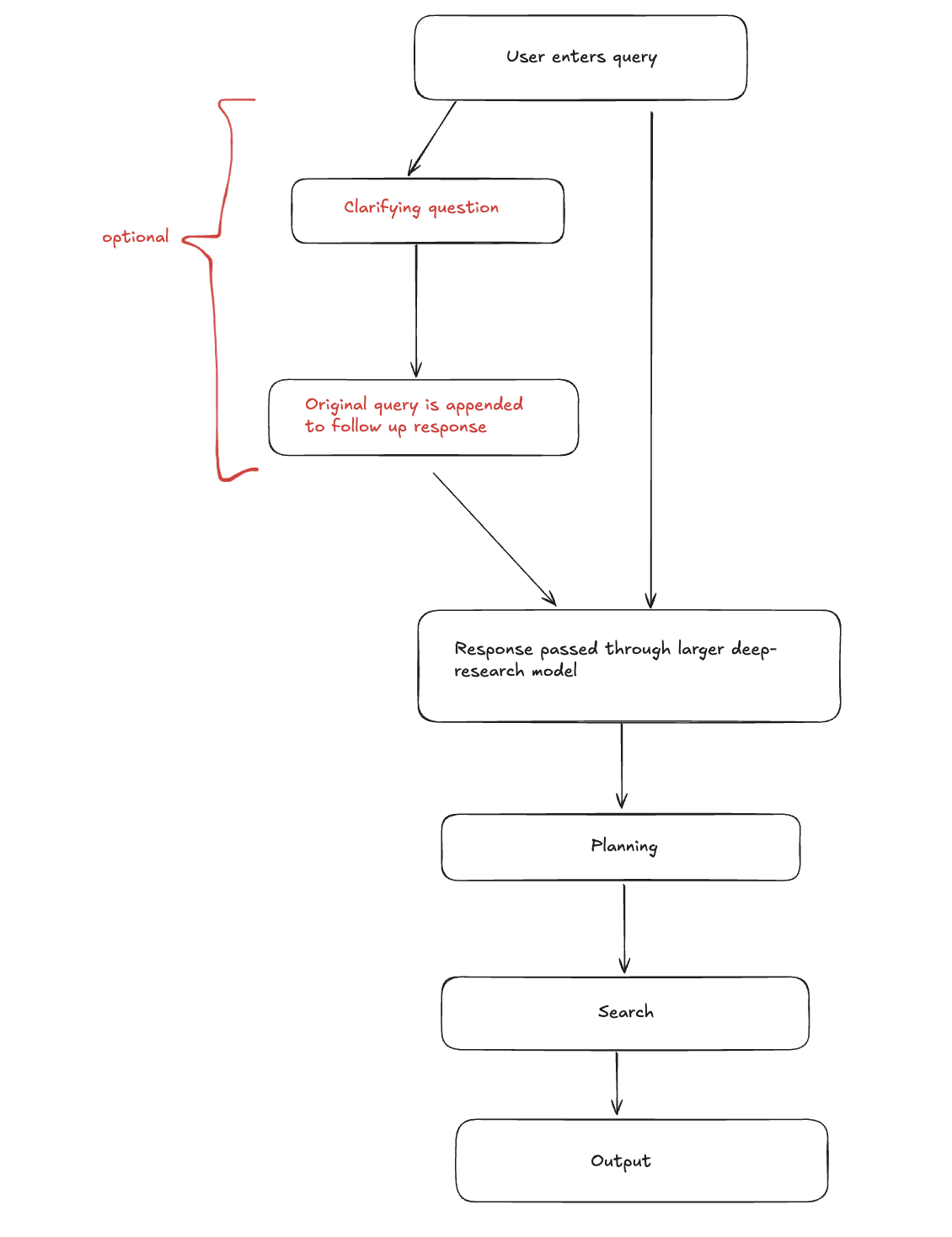
Different Flows for Different Providers
Note that not all Deep Research flows are the same as what's shown in the above diagram, only OpenAI and Kimi do this currently. Most providers would adopt a simpler approach, as shown below in the comparison table.
| Platform | Key Feature | Sources Used | Duration (mins) | Export Options | Deep Research Usage |
|---|---|---|---|---|---|
| OpenAI | Clarification questions | 10–30 | 10–15 | PDF, Docx | Paid |
| Grok's DeeperSearch | Survey notes | 70–100 | 5–10 | Ability to specify format (PDF / Markdown) | Free |
| Claude | Breadth + depth search | 100+ | 5–10 | PDF, Markdown, Artifact | Paid |
| Gemini | Editable planning | 50+ | 10–20 | Google Docs export | Free |
| Perplexity | Speed options | 50–100 | 3–5 | PDF, Markdown, Docx, Perplexity Page | Paid |
| Kimi | Interactive synthesis | 50–100 | 30–60+ | PDF, Interactive website | Free |
The following prompt was passed to the above Deep Research providers:
Generate a comprehensive report about the state of AI in the past week. Include all new model releases and notable architectural improvements from a variety of sources.
Google's generated report was the most verbose, with a whopping 23 pages that reads like a professional intelligence briefing. It opens with an executive summary, systematically categorizes developments, and provides forward-looking strategic insights—connecting OpenAI's open-weight release to broader democratization trends and linking infrastructure investments to competitive positioning.
OpenAI produced the most citation-heavy output with 134 references throughout 10 pages (albeit most of them being from the same source).
Perplexity delivered the most actionable 6-page report that maximizes information density while maintaining scannability. Despite being the shortest, it captures all major developments with sufficient context for decision-making.
Claude produced a comprehensive analysis that interestingly ignored the time constraint, covering an 8-month period from January-August 2025 instead of the requested week (Jul 31-Aug 7th 2025). Rather than cataloging recent events, Claude traced the evolution of trends over months.
Grok produced a well-structured but relatively shallow 5-page academic-style report that read more like an event catalog than strategic analysis.
Interestingly, OpenAI and Kimi—both of which require answers to their clarification questions —demonstrate the process paradox. Despite requiring user interactions before generating reports, the additional friction might not necessarily translate to quantitatively superior outputs.
Understanding Search Strategies
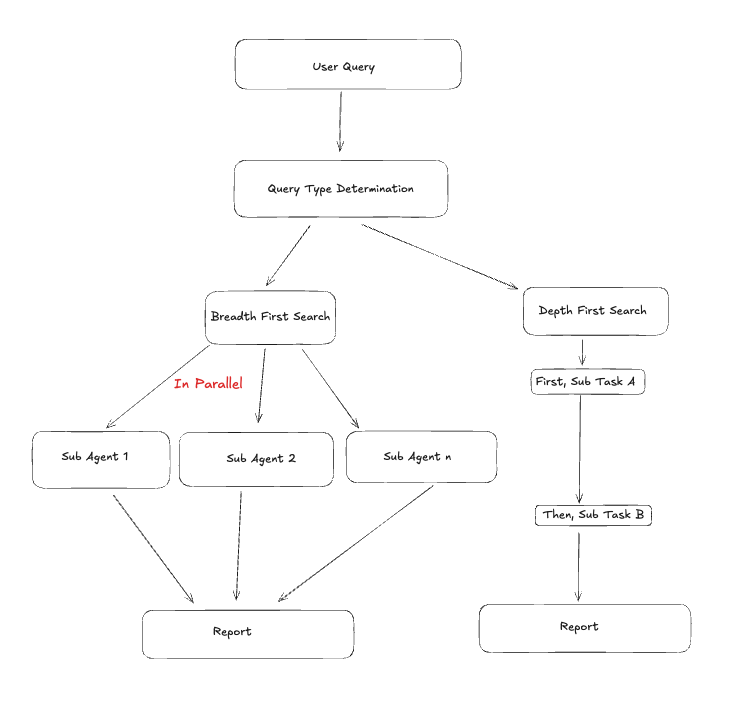
In Claude’s Deep Research (opens in a new tab), a classifier is used to determine whether a user query is breadth first or depth first. This results in a customization of the pipeline that is used for conducting research. For instance, a complex breadth first query might result in sub-agents being spun up to research various parts of the research query in parallel.
Here's a screenshot of this in action (in Claude Desktop):

Replicating Deep Research Results with Jan
Given this overview, how could we replicate this in Jan? We'll use Jan's features to build a free alternative while keeping your data local.
This is using the latest version of Jan v0.6.6. The features in this guide require at least 0.6.3 but for the best experience please use 0.6.6.
The Key: Assistants + Tools
Jan's functionality comes from combining custom assistants (opens in a new tab) with MCP search tools (opens in a new tab). This pairing allows any model—local or cloud—to follow systematic research workflows, creating our own version of deep research functionality.
What We Tested
We created a research workflow using both Jan-Nano (4B local model) (opens in a new tab), GPT-4o and o3 (via API) with identical prompts. The goal: see how close we could get to commercial Deep Research quality.
Performance Findings
| Model | Processing Time | Sources Found | Output Quality vs Commercial Deep Research |
|---|---|---|---|
| Jan-Nano (Local) | 3 minutes | Moderate | Good approximation, noticeably less depth |
| GPT-4o | 1 minute | Fewest | Fast but limited source coverage |
| o3 | 3 minutes | Most | Best of the three, but still below commercial quality |
The Reality:
- Speed vs Sources: GPT-4o prioritized speed over thoroughness, while o3 took time to gather more comprehensive sources
- Local vs Cloud: Jan-Nano matched o3's processing time but with the advantage of complete data privacy
- Quality Gap: All three models produced decent research reports, but none matched the depth and comprehensiveness of dedicated Deep Research tools like OpenAI's or Claude's offerings
- Good Enough Factor: While not matching commercial quality, the outputs were solid approximations suitable for many research needs


The Soul of a New Machine
To stay updated on all of Jan's research, subscribe to The Soul of a New Machine